ThreadLocal原理和用法
用法:
- ThreadLocal提供了线程的局部变量,每个线程都可以通过set()和get()来对这个局部变量进行操作,
但不会和其他线程的局部变量进行冲突,实现了线程的数据隔离。 - 实现线程级别的全局变量,避免使用一层层的传参。
1
2
3
4
5
6
7
8
9
10public class Requestcontext {
private static final ThreadLocal<String> traceldLocal = new ThreadLocal<>();
public static String getTraceId() {
return threadIdLocal.get();
}
public static String setTraceId (String traceld){
threadldLocal.set(traceld);
}
}1
2
3
4/*一处设置traceid*/
Requestcontext.setTraceId(UUID.randomUUID().toString());
/*另一处读取traceId,不在同一个类中调用*/
RequestContext.getTraceId();
使用举例:
java8之前的日期组件,SimpleDataFormat。当我们使用SimpleDataFormat的parse()方法,内部有一个Calendar对象,调用SimpleDataFormat的parse()方法会先调用Calendar.clear(),然后调用Calendar.add(),如果一个线程先调用了add()然后另一个线程又调用了clear(),这时候parse()方法解析的时间就不对了。从而导致了线程安全问题。当然我们可以每用一次new一个新对象出来,不过这样效率太低。
所以我们可以使用了线程池加上ThreadLocal包装SimpleDataFormat,再调用initialValue让每个线程有一个SimpleDataFormat的副本,从而解决了线程安全的问题,也提高了性能。
1 | static ThreadLocal<DateFormat> threadLocal = ThreadLocal.withInitial(SimpleDateFormat::new); |
不过Java8之后可以用java.time.format.DateTimeFormatter了。
注意(弱引用引起的内存泄露问题):
当线程没有结束,但是 ThreadLocal 已经被回收,则可能导致线程中存在ThreadLocalMap<null, Object> 的键值对,造成内存泄露。(ThreadLocal 被回收,ThreadLocal 关联的线程共享变量还存在。
解决方案:
- 使用完线程共享变量后,显式调用 ThreadLocalMap.remove 方法清除线程共享变量。
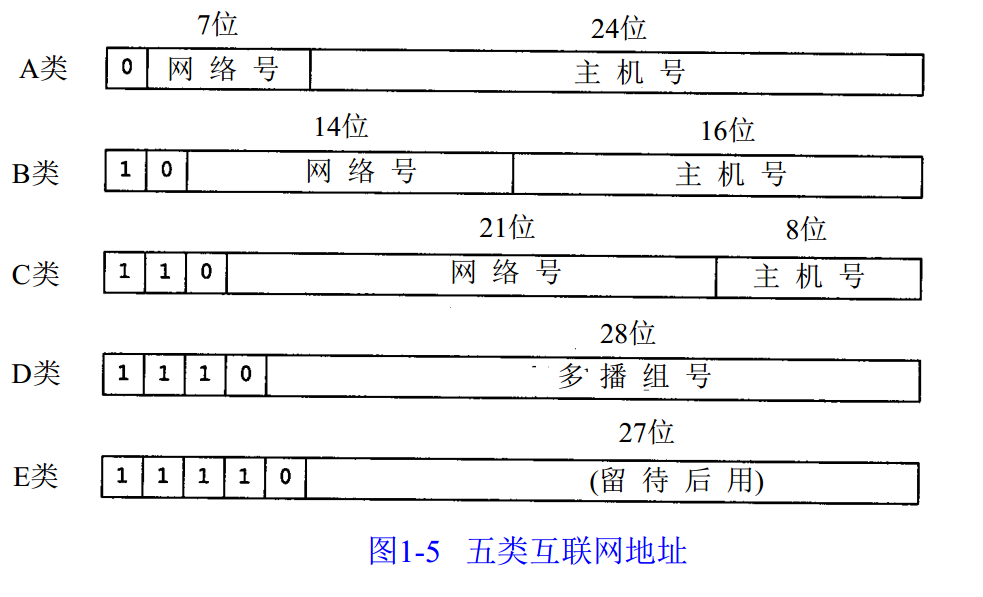
原理
简单说 ThreadLocal 就是一种以空间换时间的做法,在每个 Thread 里面维护了一个以开放定址法(区别于hashmap,没有链表,发生冲突时往后找空位就行了)实现的ThreadLocal.ThreadLocalMap,把数据进行隔离,数据不共享,自然就没有线程安全方面的问题了。
结构图: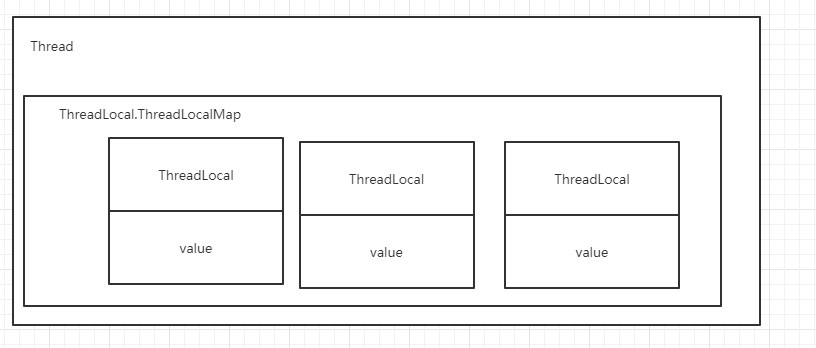
每个Thread对象中都维护了一个ThreadLocalMap,这个Map使用ThreadLocal对象作为key。
可以看到的是,ThreadLocal对象虽然是同一个,但是每个线程中的ThreadLocalMap都是单独的,所以各个线程之间是互不影响的。具体数据则时放在ThreadLocalMap的entry数组下的。
父子线程怎么共享数据
可以使用interitableThreadLocals,子线程能继承到父线程的数据,子线程中的修改不影响父线程。
private