所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
贪心算法的理解: 整个问题的最优解一定由在贪心策略中存在的子问题的最优解得来的。
mysql知识点
mysql
用 @rownum := @rownum+1 实现 rownum 功能
1 | SELECT @rownum := @rownum+1 AS rownum, |
oracle大批量数据更新操作,提供并发&小事务
oracle提供了很好用的大数据量数据更新的函数dbms_parallel_execute,改用dbms_parallel_execute执行,可以进行并行更新并且事务大小可控。
以下在命令窗口执行:
- 首先创建一个TASK,名称为update_pzjcxx:
1
exec dbms_parallel_execute.create_task('update_pzjcxx');
- 把将要更新的表按照ROWID进行分批,分到各个CHUNK中:BY_ROW:分CHUNK的类型。如果为TRUE,则后面的CHUNK_SIZE表示是行;如果是FALSE,则后面的CHUNK_SIZE表示的是BLOCK。
1
exec dbms_parallel_execute.create_chunks_by_rowid(task_name => 'update_pzjcxx',table_owner => 'V7PROD',table_name => 'KCDY_PZJCXX',by_row => true,chunk_size => 10000);
CHUNK_SIZE:CHUNK大小。如果BY_ROW为TRUE,表示多少行分为一个CHUNK;如果BY_ROW为FALSE,则表示多少块分为一个CHUNK。
基础知识HTTP
什么是HTTP?
HyperText Transfer Protocol(超文本传输协议),它是一个无状态的工作在应用层的协议.
超文本指的是HTML,css,JavaScript和图片等,HTTP的出现是为了接收和发布HTML页面,也可以用于接收一些音频,视频,文件等内容。
HTTP协议是用于客户端和服务器端之间的通信,用于客户端和服务器端之间的通信有HTTP协议和TCP/IP协议族在内的其他众多的协议。
HTTP的短连接和长连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。可以持久连接,TCP连接默认不关闭,可以被多个请求复用,只有在一段时间内,没有请求,就可以自动关闭。使用长连接的HTTP协议,会在响应头加入这行代码:
1 | // 默认: |
基础知识TCP
什么是 TCP ?
Transmission Control Protocol(传输控制协议)
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。
面向连接:一定是「一对一」才能连接,不能像 UDP 协议 可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
字节流:消息是「没有边界」的,所以无论我们消息有多大都可以进行传输。并且消息是「有序的」,当「前一个」消息没有收到的时候,即使它先收到了后面的字节已经收到,那么也不能扔给应用层去处理,同时对「重复」的报文会自动丢弃。
什么是 TCP 连接?
TCP连接主要包括三个部分:socket,序列号,窗口大小。
通过TCP连接可以控制流量,和提高可靠性。
- Socket:由 IP 地址和端口号组成
- 序列号:用来解决乱序问题等
- 窗口大小:用来做流量控制
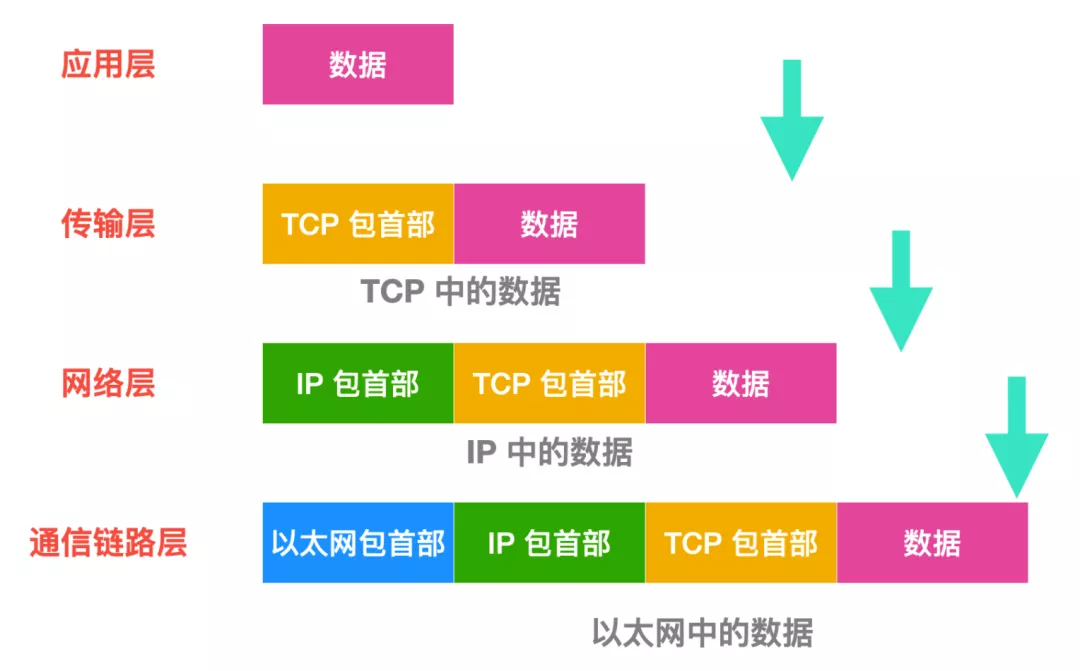
如何唯一确定一个 TCP 连接呢?
- 源地址
- 源端口
- 目的地址
- 目的端口
redis使用之缓存问题及解决方案
redis知识点整理,主要是一些最常见的问题,常见使用,Redis持久化,缓存穿透,缓存击穿,缓存雪崩,Redis分布式锁,双写一致性问题