redis的持久化策略以及集群高可用原理和常见问题解答。
spring框架_事务管理
spring事务管理
Spring定义了7种传播行为:
- propagation_requierd:如果当前没有事务,就新建一个事务,如果已存在一个事务中,
加入到这个事务中,这是Spring默认的选择。 - propagation_supports:支持当前事务,如果没有当前事务,就以非事务方法执行。
- propagation_mandatory:使用当前事务,如果没有当前事务,就抛出异常。
- propagation_required_new:新建事务,如果当前存在事务,把当前事务挂起。
- propagation_not_supported:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- propagation_never:以非事务方式执行操作,如果当前事务存在则抛出异常。
- propagation_nested:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与propagation_required类似的操作。嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
Spring事务隔离级别
Spring事务隔离级别比数据库事务隔离级别多一个default
1) DEFAULT (默认)
这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别。另外四个与JDBC的隔离级别相对应。
2) READ_UNCOMMITTED (读未提交)
这是事务最低的隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。
3) READ_COMMITTED (读已提交)
保证一个事务修改的数据提交后才能被另外一个事务读取,另外一个事务不能读取该事务未提交的数据。这种事务隔离级别可以避免脏读出现,但是可能会出现不可重复读和幻像读。
4) REPEATABLE_READ (可重复读)
这种事务隔离级别可以防止脏读、不可重复读,但是可能出现幻像读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了不可重复读。
5) SERIALIZABLE(串行化)
这是花费最高代价但是最可靠的事务隔离级别,事务被处理为顺序执行。除了防止脏读、不可重复读外,还避免了幻像读。
事务几种实现方式
- 编程式事务管理对基于 POJO 的应用来说是唯一选择。我们需要在代码中调用beginTransaction()、commit()、rollback()等事务管理相关的方法,这就是编程式事务管理。
- 基于 TransactionProxyFactoryBean的声明式事务管理
- 基于 @Transactional 的声明式事务管理
- 基于Aspectj AOP配置事务
基于 TransactionProxyFactoryBean的声明式事务管理
1 | <!-- 事务管理器 --> |
基于 @Transactional 注解的声明式事务管理
1 | public class BuyStockServiceImpl implements BuyStockService{ |
配置文件:
1 | <!-- 事务管理器 --> |
基于Aspectj AOP配置事务
1 | <context:property-placeholder location="classpath:jdbc.properties"/> |
springboot框架总述
SpringBoot主要特性
Spring boot 简化了使用 Spring 的难度,简省了繁重的配置(版本管理,依赖导入),提供了各种启动器,开发者能快速上手。
SpringBoot的版本控制
pom.xml中有父项目
spring-boot-dependencies:核心依赖在父工程中
我们在写或者应用引入一些springboot的依赖的时候,不需要指定版本,因为有相关版本库。
SpringBoot的自动装配
SpringBoot 自动配置主要通过 @EnableAutoConfiguration, @Conditional, @EnableConfigurationProperties 或者 @ConfigurationProperties 等几个注解来进行自动配置完成的。
@EnableAutoConfiguration 开启自动配置,主要作用就是调用 Spring-Core 包里的 loadFactoryNames(),将 autoconfig 包里的已经写好的自动配置加载进来。
@Conditional 条件注解,通过判断类路径下有没有相应配置的 jar 包来确定是否加载和自动配置这个类。
@EnableConfigurationProperties 的作用就是,给自动配置提供具体的配置参数,只需要写在 application.properties 中,就可以通过映射写入配置类的 POJO 属性中。
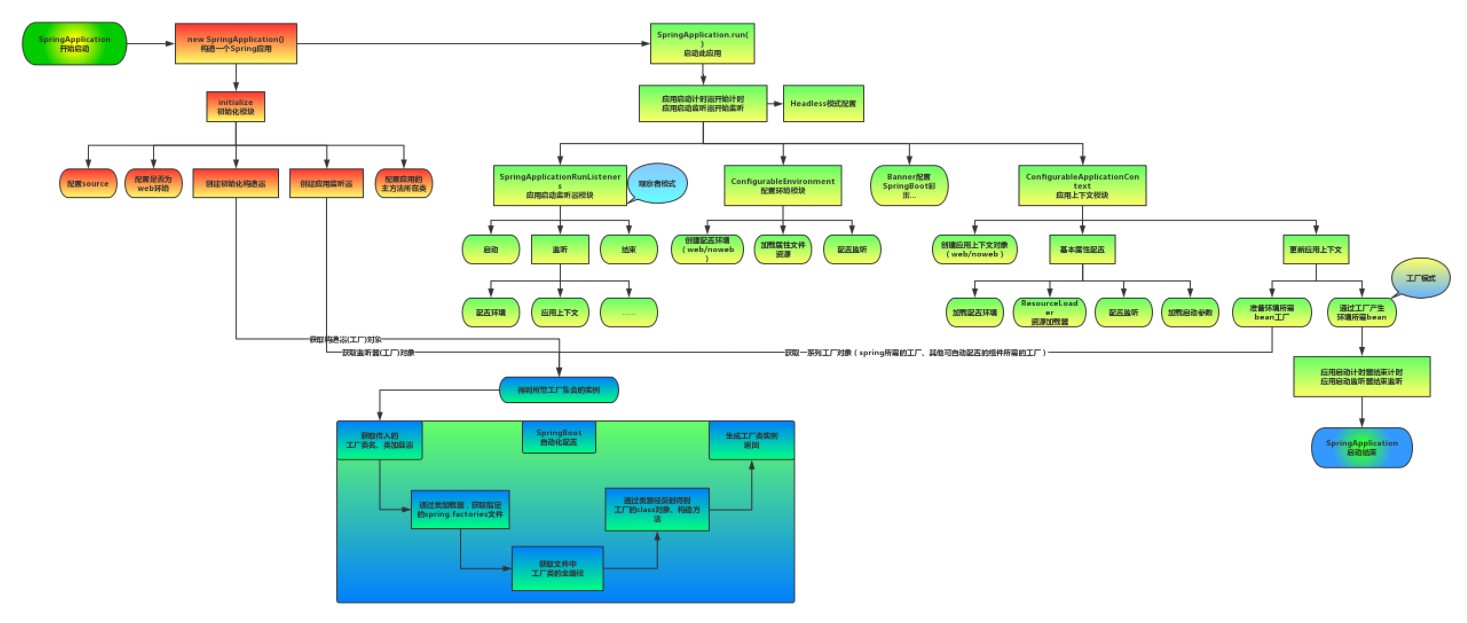
该配置模块的主要使用到了SpringFactoriesLoader,即Spring工厂加载器,该对象提供了loadFactoryNames()方法,入参为factoryClass和classLoader,即需要传入上图中的工厂类名称和对应的类加载器,方法会根据指定的classLoader,加载该类加器搜索路径下的指定文件,即指定的配置文件META-INF/spring.factories,传入的工厂类为接口,而文件中对应的类则是接口的实现类,或最终作为实现类,所以文件中一般为一对多的类名集合,获取到这些实现类的类名后,loadFactoryNames方法返回类名集合,方法调用方得到这些集合后,再通过反射获取这些类的类对象、构造方法,最终生成实例。

什么是 Spring Boot Stater ?
启动器是一套方便的依赖描述符,它可以放在自己的程序中。你可以一站式的获取你所需要的 Spring 和相关技术,而不需要依赖描述符的通过示例代码搜索和复制黏贴的负载。
限流_sentinel
Sentinel
主要概念相关
Sentinel 是面向分布式服务架构的高可用流量防护组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性。
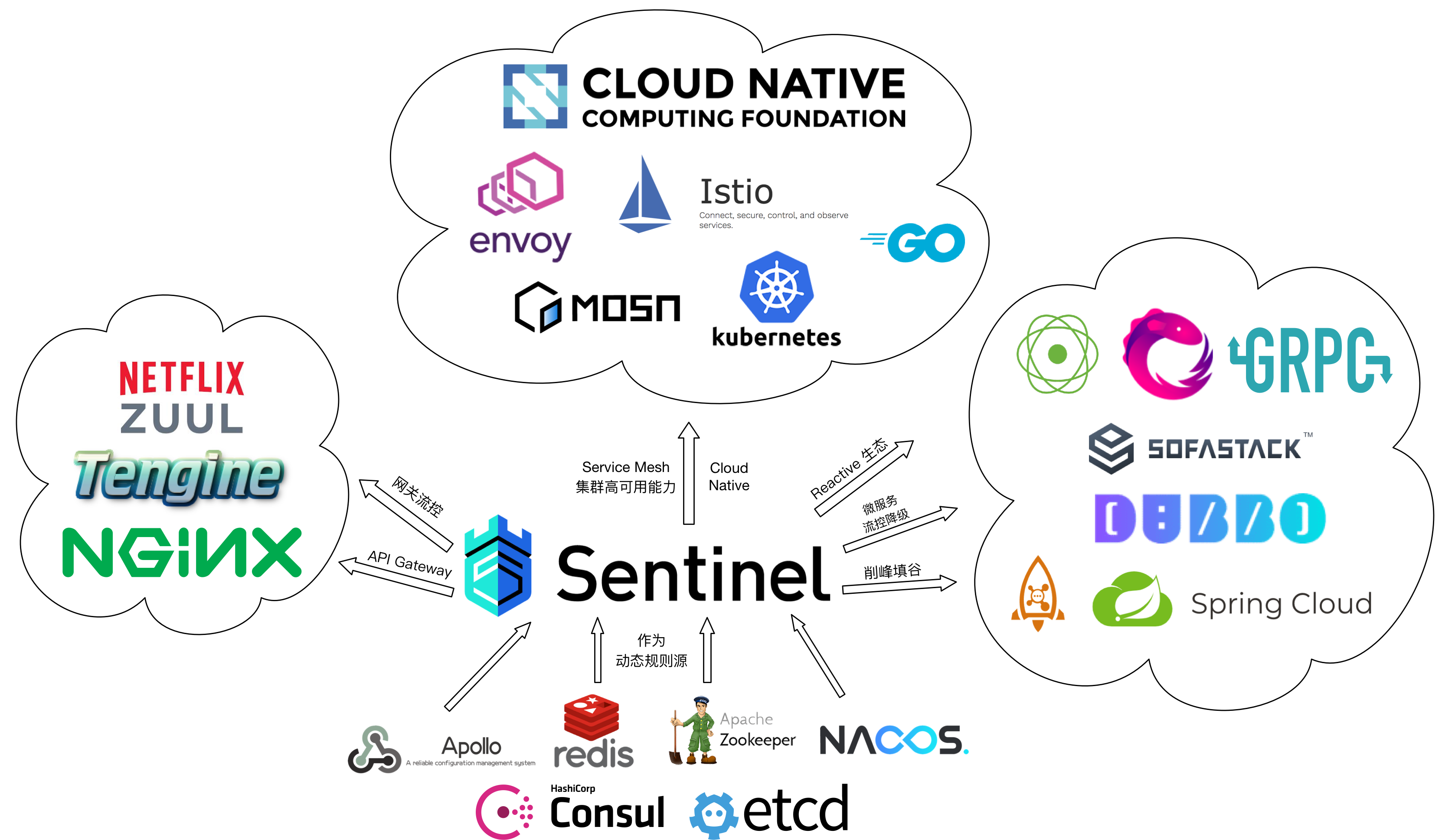
Sentinel 基本概念
资源
资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则
围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
使用
基本使用 - 资源与规则
集成apollo
针对来源进行限流
1.首先我们要自定义来源解析RequestOriginParser
1 |
|
2.接下来我们设置来源 ,填入限制的ip,
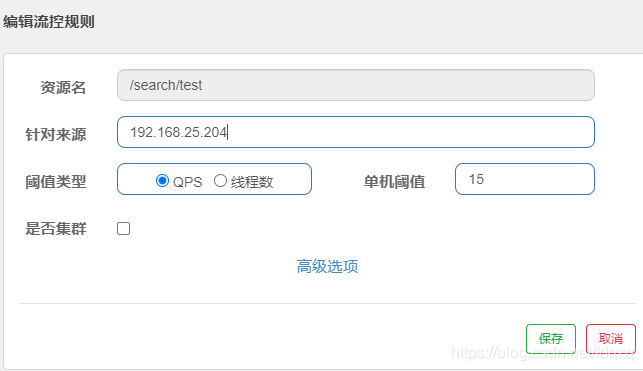
3.即可实现针对ip的限流
redis要点梳理和实战
redis基础使用笔记,相关的数据结构
springMVC框架总述
什么是MVC
- M代表模型(Model)
模型其实就是数据,dao,bean - V代表视图(View)
网页,jsp等用来展示数据的模型 - C代表Controller
把不同的数据展示在不同的视图上,处理请求的分发,Servlet扮演的就是这样的角色
SpringMVC的流程
用户发送请求至前端控制器DispatcherServlet;
DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handler;
处理器映射器根据请求url找到具体的处理器Handler,生成处理器对象及处理器拦截器(如果有则生成),一并返回给DispatcherServlet;
DispatcherServlet 调用 HandlerAdapter处理器适配器,请求执行Handler;
HandlerAdapter 经过适配调用 具体处理器进行处理业务逻辑;
Handler执行完成返回ModelAndView;
HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
ViewResolver解析后返回具体View;
DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
DispatcherServlet响应用户。
springcloud_五大组件
SpringCloud进阶
- javase
- 数据库
- [] 前端
- [] servlet
- [] Http
- Mybatis
- Spring
- [] SpringMVC
- [] SpringBoot
- Dubbo,zookeeper,分布式基础
- maven
总结一下SpringCloud结果核心组件:
Eureka:个服务启动时,Eureka会将服务注册到EurekaService,并且EurakeClient还可以返回过来从EurekaService拉去注册表,从而知道服务在哪里
Ribbon:服务间发起请求的时候,基于Ribbon服务做到负载均衡,从一个服务的对台机器中选择一台
目前,在Spring cloud 中服务之间通过restful方式调用有两种方式
- restTemplate+Ribbon
- feign
Feign:RPC框架,基于fegin的动态代理机制,根据注解和选择机器,拼接Url地址,发起请求,Feign是Netflix开发的声明式、模板化的HTTP客户端, Feign可以帮助我们更快捷、优雅地调用HTTP API。
Hystrix:发起的请求是通过Hystrix的线程池来走,不同的服务走不同的线程池,实现了不同的服务调度隔离,避免服务雪崩的问题
Zuul:如果前端后端移动端调用后台系统,统一走zull网关进入,有zull网关转发请求给对应的服务
Apollo(阿波罗)是携程框架部门研发的配置管理平台,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性。Apollo配置中心设计
Ribbon
Ribbon 是一个基于 HTTP 和 TCP 客户端的负载均衡器
它可以在客户端配置 ribbonServerList(服务端列表),然后轮询请求以实现均衡负载
它在联合 Eureka 使用时
ribbonServerList 会被 DiscoveryEnabledNIWSServerList 重写,扩展成从 Eureka 注册中心获取服务端列表
同时它也会用 NIWSDiscoveryPing 来取代 IPing,它将职责委托给 Eureka 来确定服务端是否已经启动
Feign
Spring Cloud Netflix 的微服务都是以 HTTP 接口的形式暴露的,所以可以用 Apache 的 HttpClient 或 Spring 的 RestTemplate 去調用,而 Feign 是一個使用起來更加方便的 HTTP 客戶端,它用起來就好像調用本地方法一樣,完全感覺不到是調用的遠程方法
总结起来就是:发布到注册中心的服务方接口,是 HTTP 的,也可以不用 Ribbon 或者 Feign,直接浏览器一样能够访问
只不过 Ribbon 或者 Feign 调用起来要方便一些,最重要的是:它俩都支持软负载均衡
注意:spring-cloud-starter-feign 里面已经包含了 spring-cloud-starter-ribbon(Feign 中也使用了 Ribbon)
从实践上看,采用feign的方式更优雅(feign内部也使用了ribbon做负载均衡)。
Spring Cloud 和dubbo区别?
其实Dubbo仅仅是一个RPC框架,实现Java程序的远程调用,而Spring Cloud则是实施微服务的一系列套件,包括:服务注册与发现、断路器、服务状态监控、配置管理、智能路由、一次性令牌、全局锁、分布式会话管理、集群状态管理等
(1)服务调用方式 dubbo是RPC,springcloud是 Rest Api
(2)注册中心,dubbo 是zookeeper springcloud是eureka,也可以是zookeeper
(3)服务网关,dubbo本身没有实现,只能通过其他第三方技术整合,springcloud有Zuul路由网关,作为路由服务器,进行消费者的请求分发,springcloud支持断路器,与git完美集成配置文件支持版本控制,事物总线实现配置文件的更新与服务自动装配等等一系列的微服务架构要素。
常见的RPC组件:
- RMI(远程方法调用)
JAVA自带的远程方法调用工具,不过有一定的局限性,毕竟是JAVA语言最开始时的设计,后来很多框架的原理都基于RMI。
Hessian(基于HTTP的远程方法调用)
基于HTTP协议传输,在性能方面还不够完美,负载均衡和失效转移依赖于应用的负载均衡器,Hessian的使用则与RMI类似,区别在于淡化了Registry的角色,通过显示的地址调用,利用HessianProxyFactory根据配置的地址create一个代理对象,另外还要引入Hessian的Jar包。
Dubbo(淘宝开源的基于TCP的RPC框架)
基于Netty的高性能RPC框架,是阿里巴巴开源的,总体原理如下:
限流算法
在高并发的网络应用中,保护系统的稳定性和可用性是至关重要的。
缓存、熔断、降级、限流
缓存的目的是为了降低系统的访问延迟,提高系统能力,给用户更好的体验
熔断的目的是为了在发现某个服务故障熔断对下游依赖的请求,减少不必要的损耗
降级的目的是为了在系统在某个环节故障(比如某个下游故障)不影响整体核心链路,比如返回作者列表,关注服务故障了获取不了关注真实的关注情况,这种情况可以考虑降级关注按钮,全部显示为未关注
限流的目的是为了保证系统处理的请求量在可以承受的范围内,防止突发流量压垮系统,保证系统稳定性。
目标:限定请求量在系统可承受范围内。
mysql_优化系列_索引优化
模糊匹配like %%怎么优化
- 开启ICP(索引条件下推)
- 索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。
- 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器 。
- 索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。****
可以通过索引筛选,返回给Server层筛选后的记录,减少不必要的IO开销。
如果where后只有一个 like ‘%xxx%’条件,表有主键的前提下,可以通过子查询优化
1 | select * from users01 a , |
- 建立全文索引
两种检索模式
MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
IN NATURAL LANGUAGE MODE:默认模式,以自然语言的方式搜索,AGAINST(‘看风’ IN NATURAL LANGUAGE MODE ) 等价于AGAINST(‘看风’)。
IN BOOLEAN MODE:布尔模式,表是字符串前后的字符有特殊含义,如查找包含SK,但不包含Lyn的记录,可以用+,-符号。
AGAINST(‘+SK -Lyn’ in BOOLEAN MODE);
创建全文索引:
1 | alter table users01 add fulltext index idx_full_nickname(nickname) with parser ngram; |
改写like语句:
1 | select * from users01 where match(nickname) against('看风'); |
- 生成列(虚拟列)
对于where条件后的 like ‘%xxx’ 是无法利用索引扫描,可以利用MySQL 5.7的生成列模拟函数索引的方式解决,具体步骤如下:
利用内置reverse函数将like ‘%风云’反转为like ‘云风%’,基于此函数添加虚拟生成列。
在虚拟生成列上创建索引。
将SQL改写成通过生成列like reverse(‘%风云’)去过滤,走生成列上的索引。
建立生成列1
alter table users01 add reverse_nickname varchar(200) generated always as (reverse(nickname));
索引很长的字段怎么优化?
有时候需要索引很长的字符(例如BLOB,TEXT,或者很长的VARCHAR),这样会使得索引又大又慢。
- 改用哈希索引。
InnoDB是支持Btree索引,但不显式支持hash索引。可以使用生成列来间接使用哈希索引。 - 使用字符串的前几个字符作为索引(即前缀索引)。
1 | ALTER TABLE `city_demo` ADD INDEX `idx_city` (`city`(7)) USING BTREE ; |
当然在选择前缀时要选择合适的前缀索引长度,保持好的选择性。其方法主要是计算数据分布。
1 | -- 查询重复次数最多的10条完整城市名称及其数量(图1) |
MRR
MRR全称是Multi-Range Read,是MYSQL5.6优化器的一个新特性,在MariaDB5.5也有这个特性。优化的功能在使用二级索引做范围扫描的过程中减少磁盘随机IO和减少主键索引的访问次数。二级索引通过将主键放在buffer中排序将随机IO转换为顺序IO。对于随机读写能力较弱的机械硬盘有比较大优化。
Java基础提升_数据结构篇
List,set,map,queue,stack。 ArrayList、LinkedList、Vector的区别。 hashmap,hashtable,concurrentHashMap,hashtable比较